


































































































































































































































Creación de Canalizaciones de Datos Eficientes para IA y PLN en AWS
En un mundo cada vez más impulsado por la inteligencia artificial (IA) y el procesamiento del lenguaje natural (NLP), la […]

En un mundo cada vez más impulsado por la inteligencia artificial (IA) y el procesamiento del lenguaje natural (NLP), la demanda de aplicaciones avanzadas en estos campos ha incrementado significativamente. Las empresas están buscando aprovechar los conocimientos basados en datos y la automatización de procesos para mejorar su rendimiento y competitividad. Para lograr esto, es esencial contar con un pipeline de datos que permita la ingesta, procesamiento y generación de salidas que faciliten el entrenamiento y la toma de decisiones a gran escala.
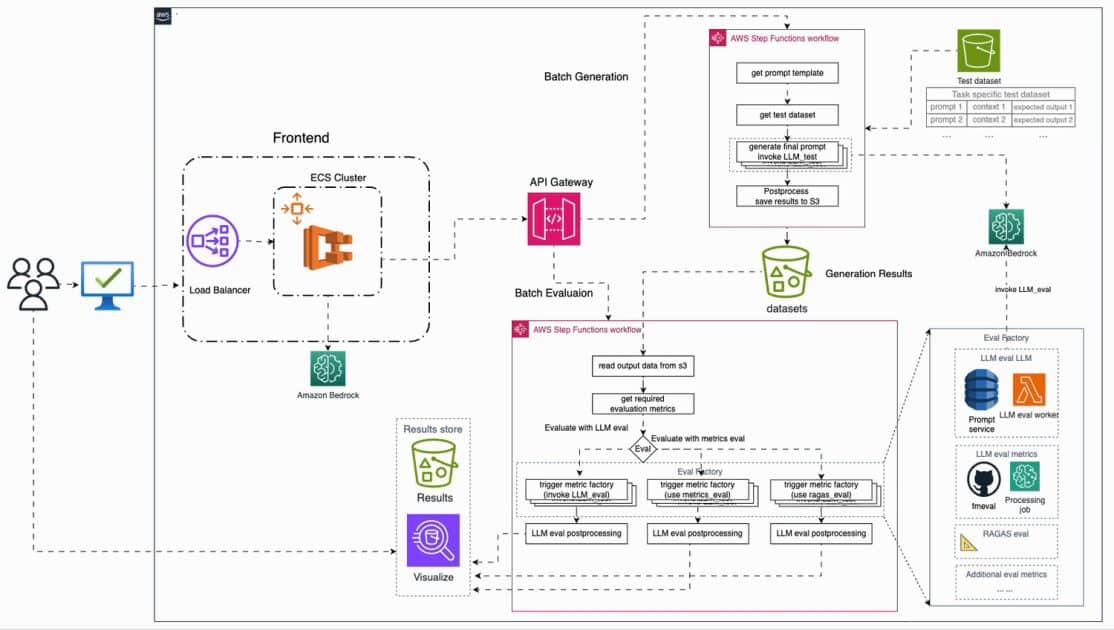
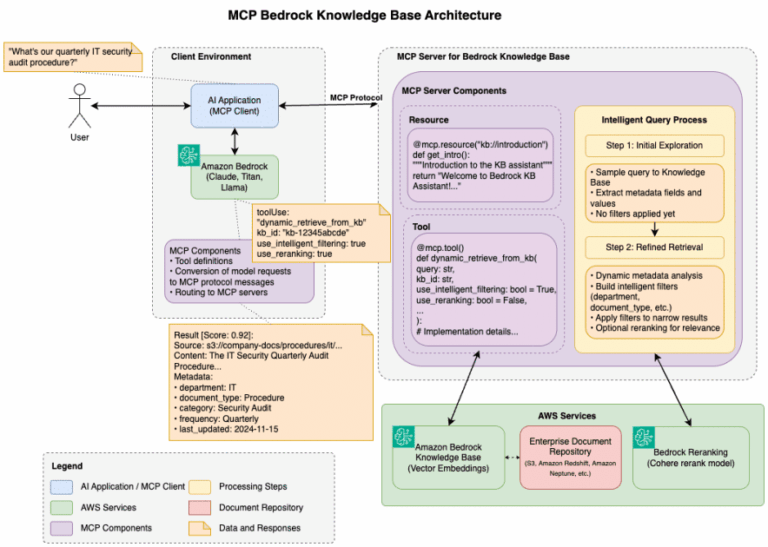
Amazon Web Services (AWS) se ha posicionado como el estándar en la nube por su escalabilidad y eficiencia al construir dichos pipelines. Implementar un pipeline de alto rendimiento utilizando servicios básicos de AWS, como Amazon S3, AWS Lambda, AWS Glue y Amazon SageMaker, se está convirtiendo en una práctica común entre las organizaciones que buscan implementar soluciones de IA y NLP.
La infraestructura sólida, el ecosistema de servicios diverso y la integración fluida con flujos de trabajo de machine learning y NLP hacen de AWS una opción preferida para estas aplicaciones. Aunque plataformas como Azure y Google Cloud ofrecen alternativas, AWS destaca en términos de facilidad de uso y fiabilidad operativa. Uno de los mayores beneficios de utilizar AWS es su capacidad de escalar automáticamente, asegurando un rendimiento constante sin importar el volumen de datos que se maneje.
Además, AWS proporciona flexibilidad mediante una variedad de servicios que se adaptan perfectamente a las necesidades de un pipeline de datos. Por ejemplo, Amazon S3 se utiliza para el almacenamiento, mientras que AWS Glue se encarga de la extracción, transformación y carga (ETL) de datos. Esto permite que las organizaciones integren fácilmente modelos de ML y NLP, optimizando así sus aplicaciones impulsadas por IA.
El modelo de precios de «pago por uso» de AWS asegura que las empresas de todos los tamaños puedan operar de manera eficiente sin comprometer su presupuesto. Con una infraestructura global que abarca numerosos centros de datos, AWS garantiza alta disponibilidad y baja latencia para usuarios en todo el mundo. Además, sus robustas características de seguridad, como cifrado y gestión de identidades, ayudan a salvaguardar los datos durante todo el proceso.
Para diseñar un pipeline eficiente, es crucial seguir un enfoque estructurado. Esto incluye pasos como la ingesta de datos, donde AWS ofrece diversas metodologías según la naturaleza del dato; la transformación y preparación de la información para adecuarla a modelos de IA y NLP; y el entrenamiento y la inferencia de modelos utilizando Amazon SageMaker.
Finalmente, el monitoreo regular y la optimización del pipeline aseguran el mantenimiento del rendimiento. Herramientas como Amazon CloudWatch y SageMaker Debugger permiten a las organizaciones seguir de cerca la efectividad de sus modelos en producción, facilitando ajustes necesarios que aseguran que se mantenga la calidad del análisis y la toma de decisiones.
La creciente importancia de la IA y el NLP subraya la necesidad de crear pipelines de datos efectivos y escalables. AWS, con su oferta diversa y potente, se posiciona como un aliado estratégico en el desarrollo de soluciones que no solo responden a las demandas actuales, sino que también permiten a las organizaciones avanzar en sus objetivos tecnológicos y comerciales.